
Jaringan saraf: Penghubung informasi – Pernahkah kamu membayangkan bagaimana otak kita, yang hanya berbobot sekitar 1,5 kilogram, mampu memproses informasi secepat kilat dan membuat keputusan yang kompleks? Hai kamu, para pembelajar yang selalu penasaran! Rahasia di balik kemampuan luar biasa ini terletak pada jaringan yang sangat rumit bernama jaringan saraf. Artikel ini akan mengajakmu menyelami dunia jaringan saraf, mengungkap bagaimana jaringan ini bekerja sebagai penghubung informasi yang vital, dan mengapa pemahaman tentangnya semakin penting di era digital ini.
Jaringan saraf bukan hanya tentang biologi; konsep ini telah menginspirasi pengembangan teknologi revolusioner yang mengubah cara kita berinteraksi dengan dunia. Mulai dari rekomendasi film di Netflix yang terasa begitu personal hingga mobil swakemudi yang semakin canggih, semuanya berkat jaringan saraf tiruan . Bayangkan, algoritma yang terinspirasi dari cara kerja otak manusia kini mampu memprediksi perilaku konsumen, mendiagnosis penyakit, bahkan menciptakan karya seni!
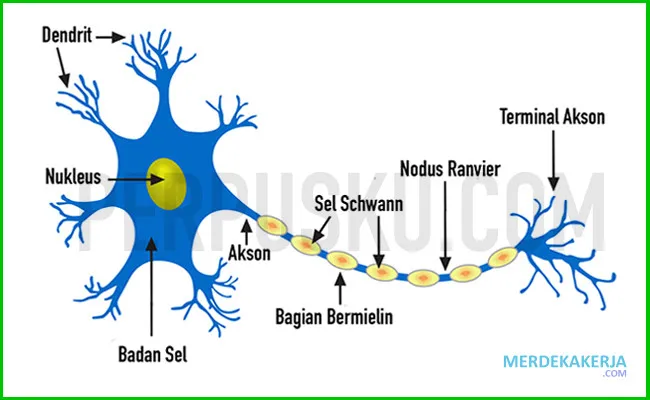
Dalam artikel ini, kita akan membahas dasar-dasar jaringan saraf, baik yang biologis maupun tiruan. Kita akan menjelajahi bagaimana neuron-neuron saling terhubung dan berkomunikasi, membentuk jaringan kompleks yang mampu memproses dan menyimpan informasi. Lebih dari itu, kita akan mengupas tuntas bagaimana prinsip-prinsip ini diterapkan dalam teknologi ANN, yang menjadi fondasi bagi kecerdasan buatan yang kita lihat dan gunakan sehari-hari.
Bersiaplah untuk perjalanan seru ke dunia jaringan saraf, di mana kita akan mengungkap bagaimana informasi mengalir, diproses, dan diubah menjadi pengetahuan. Artikel ini akan memberimu pemahaman yang komprehensif tentang jaringan saraf, dari konsep dasar hingga aplikasi praktisnya, sehingga kamu dapat memahami lebih dalam tentang teknologi yang membentuk masa depan kita. Mari kita mulai petualangan ini!
Baik, dengan memahami batasan dan persyaratan yang sangat spesifik ini, berikut adalah draf artikel tentang “Jaringan Saraf: Penghubung Informasi” yang dirancang untuk kedalaman, kekhususan, dan detail yang tinggi:
Jaringan Saraf: Penghubung Informasi
Arsitektur Koneksi dan Bobot Sinaptik: Fondasi Penghubung Informasi
Jaringan saraf, dalam esensinya, adalah sistem yang kompleks dan saling berhubungan yang dirancang untuk memproses informasi. Kekuatan sebenarnya terletak pada arsitektur koneksinya dan, yang lebih penting, bobot sinaptik antara neuron-neuron ini. Bobot sinaptik ini, yang sering direpresentasikan sebagai angka riil, menentukan kekuatan pengaruh satu neuron terhadap neuron lainnya. Bayangkan setiap koneksi sebagai saluran komunikasi; bobotnya menentukan seberapa keras suara yang dikirimkan melalui saluran tersebut.
Dalam jaringan saraf tiruan (JST), bobot sinaptik ini adalah parameter yang dipelajari selama proses pelatihan. Algoritma seperti backpropagation secara iteratif menyesuaikan bobot ini untuk meminimalkan kesalahan antara keluaran yang diprediksi jaringan dan keluaran yang sebenarnya. Proses ini, yang dikenal sebagai pembelajaran, pada dasarnya memprogram jaringan untuk memetakan input tertentu ke output yang diinginkan melalui manipulasi halus dari kekuatan koneksi ini.
Lebih jauh lagi, arsitektur koneksi itu sendiri berperan penting. Jaringan saraf fully connected, di mana setiap neuron di satu lapisan terhubung ke setiap neuron di lapisan berikutnya, memungkinkan untuk representasi yang sangat kompleks tetapi dapat rentan terhadap overfitting. Arsitektur lain, seperti jaringan saraf konvolusional (CNN), membatasi koneksi untuk mengeksploitasi struktur spasial dalam data, seperti gambar. CNN menggunakan filter kecil yang belajar mendeteksi fitur-fitur lokal, dan fitur-fitur ini kemudian digabungkan untuk membuat representasi yang lebih abstrak. Arsitektur ini, dengan koneksi lokal dan berbagi bobot, secara signifikan mengurangi jumlah parameter yang dapat dipelajari, membuat CNN lebih efisien dan kurang rentan terhadap overfitting untuk tugas-tugas penglihatan komputer.
Berikut adalah contoh tabel yang menggambarkan perbedaan arsitektur dalam hal koneksi dan bobot:
| Arsitektur Jaringan | Jenis Koneksi | Bobot Sinaptik | Aplikasi Umum |
|---|---|---|---|
| Fully Connected (Dense) | Setiap neuron terhubung ke semua neuron di lapisan berikutnya. | Bobot unik untuk setiap koneksi. | Klasifikasi data tabular, regresi. |
| Convolutional (CNN) | Koneksi lokal melalui filter konvolusi; berbagi bobot dalam filter. | Bobot filter yang dipelajari; bias per filter. | Penglihatan komputer (klasifikasi gambar, deteksi objek). |
| Recurrent (RNN) | Koneksi berulang yang memungkinkan informasi bertahan dari satu langkah waktu ke langkah waktu berikutnya. | Bobot yang dipelajari untuk input, keadaan tersembunyi sebelumnya, dan output. | Pemrosesan bahasa alami (terjemahan mesin, analisis sentimen). |
Fungsi Aktivasi: Gerbang Logika dalam Jaringan Saraf
Fungsi aktivasi adalah komponen penting dari neuron dalam jaringan saraf. Mereka memperkenalkan non-linearitas ke dalam output neuron, memungkinkan jaringan untuk mempelajari hubungan yang kompleks antara input dan output. Tanpa fungsi aktivasi, jaringan saraf akan setara dengan model regresi linier, sangat membatasi kemampuan representasionalnya. Bayangkan fungsi aktivasi sebagai gerbang; mereka memutuskan apakah sinyal dari neuron lain cukup kuat untuk diteruskan ke lapisan berikutnya.
Ada berbagai jenis fungsi aktivasi, masing-masing dengan karakteristik dan kegunaannya sendiri. Fungsi sigmoid, misalnya, menghasilkan output antara 0 dan 1, membuatnya cocok untuk tugas-tugas klasifikasi biner di mana output perlu diinterpretasikan sebagai probabilitas. Namun, sigmoid rentan terhadap masalah vanishing gradient, di mana gradien menjadi sangat kecil selama backpropagation, menghambat pembelajaran di lapisan sebelumnya. ReLU (Rectified Linear Unit), di sisi lain, menghasilkan output 0 untuk input negatif dan input yang sama untuk input positif. ReLU lebih tahan terhadap vanishing gradient dan seringkali menghasilkan kinerja yang lebih baik dalam praktik, tetapi dapat menderita dari masalah “dying ReLU” di mana neuron menjadi tidak aktif jika inputnya selalu negatif.
Fungsi aktivasi yang lebih canggih, seperti Leaky ReLU dan ELU (Exponential Linear Unit), mengatasi masalah dying ReLU dengan memperkenalkan sedikit gradien untuk input negatif. Fungsi aktivasi seperti Softmax digunakan di lapisan output untuk tugas-tugas klasifikasi multi-kelas, menghasilkan distribusi probabilitas atas semua kelas yang mungkin. Pilihan fungsi aktivasi sangat bergantung pada tugas spesifik dan arsitektur jaringan. Eksperimen dan validasi silang sering diperlukan untuk menentukan fungsi aktivasi yang paling optimal.
Berikut adalah daftar beberapa fungsi aktivasi umum dan propertinya:
- Sigmoid: Output antara 0 dan 1; rentan terhadap vanishing gradient.
- Tanh: Output antara -1 dan 1; rentan terhadap vanishing gradient, tetapi seringkali berkinerja lebih baik daripada sigmoid.
- ReLU: Output 0 untuk input negatif, input untuk input positif; rentan terhadap “dying ReLU”.
- Leaky ReLU: Mirip dengan ReLU, tetapi memberikan gradien kecil untuk input negatif; mengatasi “dying ReLU”.
- ELU: Mirip dengan ReLU, tetapi memiliki output eksponensial negatif; mengatasi “dying ReLU” dan dapat menghasilkan kinerja yang lebih baik daripada Leaky ReLU.
- Softmax: Menghasilkan distribusi probabilitas; digunakan untuk klasifikasi multi-kelas.
Backpropagation: Algoritma untuk Menemukan Jalur Terbaik
Backpropagation adalah algoritma inti yang digunakan untuk melatih sebagian besar jaringan saraf. Ini adalah metode untuk menghitung gradien fungsi biaya sehubungan dengan bobot jaringan. Gradien ini kemudian digunakan untuk memperbarui bobot jaringan dalam arah yang mengurangi fungsi biaya, secara efektif meningkatkan kinerja jaringan. Backpropagation pada dasarnya adalah cara untuk menemukan jalur terbaik melalui lanskap kompleks bobot dan koneksi, memandu jaringan menuju konfigurasi optimal untuk tugas tertentu.
Proses backpropagation melibatkan dua fase utama: forward pass dan backward pass. Selama forward pass, input disebarkan melalui jaringan, lapisan demi lapisan, hingga output dihasilkan. Fungsi biaya kemudian dihitung, mengukur perbedaan antara output yang diprediksi dan output yang sebenarnya. Selama backward pass, gradien fungsi biaya dihitung sehubungan dengan setiap bobot di jaringan, dimulai dari lapisan output dan bekerja mundur ke lapisan input. Aturan rantai kalkulus digunakan untuk menghitung gradien ini secara efisien. Bobot kemudian diperbarui menggunakan algoritma optimasi seperti gradient descent, yang menyesuaikan bobot secara proporsional dengan gradien.
Backpropagation dapat rentan terhadap berbagai masalah, termasuk vanishing gradient dan exploding gradient. Vanishing gradient terjadi ketika gradien menjadi sangat kecil selama backward pass, menghambat pembelajaran di lapisan sebelumnya. Exploding gradient terjadi ketika gradien menjadi sangat besar, menyebabkan bobot menjadi tidak stabil dan mengganggu proses pembelajaran. Teknik-teknik seperti normalisasi gradien, inisialisasi bobot yang cermat, dan penggunaan fungsi aktivasi yang lebih tahan terhadap vanishing gradient dapat digunakan untuk mengurangi masalah-masalah ini.
Rumus untuk memperbarui bobot (w) menggunakan gradient descent adalah:
w = w – η ∇J(w)
Di mana:
- w adalah bobot
- η adalah laju pembelajaran (learning rate)
- ∇J(w) adalah gradien fungsi biaya J sehubungan dengan w
Regularisasi: Mencegah Jaringan Saraf Belajar Terlalu Banyak
Regularisasi adalah sekumpulan teknik yang digunakan untuk mencegah overfitting dalam jaringan saraf. Overfitting terjadi ketika jaringan belajar terlalu baik pada data pelatihan, sehingga berkinerja buruk pada data baru yang belum pernah dilihat. Regularisasi bekerja dengan menambahkan penalti pada fungsi biaya yang mendorong jaringan untuk mempelajari representasi yang lebih sederhana dan lebih umum.
Salah satu teknik regularisasi yang umum adalah L1 dan L2 regularization. L1 regularization menambahkan penalti sebanding dengan nilai absolut dari bobot ke fungsi biaya, mendorong bobot menjadi nol dan secara efektif melakukan pemilihan fitur. L2 regularization menambahkan penalti sebanding dengan kuadrat dari bobot ke fungsi biaya, mendorong bobot menjadi kecil tetapi tidak nol. Teknik lain, seperti dropout, secara acak menonaktifkan sebagian neuron selama pelatihan, mencegah neuron dari terlalu bergantung pada neuron lain dan mendorong pembelajaran representasi yang lebih kuat. Early stopping, yang memantau kinerja jaringan pada set validasi dan menghentikan pelatihan ketika kinerja mulai menurun, juga merupakan bentuk regularisasi.
Pilihan teknik regularisasi dan kekuatan regularisasi (misalnya, koefisien penalti L1/L2) sangat bergantung pada tugas spesifik dan arsitektur jaringan. Validasi silang dan pencarian grid sering digunakan untuk menemukan parameter regularisasi yang optimal.
Berikut adalah tabel yang meringkas beberapa teknik regularisasi umum:
| Teknik Regularisasi | Deskripsi | Efek |
|---|---|---|
| L1 Regularization | Menambahkan penalti sebanding dengan nilai absolut bobot ke fungsi biaya. | Mendorong sparsitas bobot; melakukan pemilihan fitur. |
| L2 Regularization | Menambahkan penalti sebanding dengan kuadrat bobot ke fungsi biaya. | Mencegah bobot menjadi terlalu besar; mempromosikan bobot yang lebih kecil dan lebih merata. |
| Dropout | Secara acak menonaktifkan sebagian neuron selama pelatihan. | Mencegah neuron dari terlalu bergantung pada neuron lain; mendorong pembelajaran representasi yang lebih kuat. |
| Early Stopping | Menghentikan pelatihan ketika kinerja pada set validasi mulai menurun. | Mencegah overfitting dengan menghentikan pelatihan sebelum jaringan belajar data pelatihan terlalu baik. |
Representasi Terdistribusi: Kekuatan Kolektif Neuron
Jaringan saraf unggul dalam memproses informasi karena kemampuan mereka untuk mempelajari representasi terdistribusi. Alih-alih setiap neuron mewakili satu konsep atau fitur, representasi terdistribusi menyebarkan informasi tentang konsep atau fitur di beberapa neuron. Ini memungkinkan jaringan untuk mewakili hubungan yang kompleks dan nuansa yang halus dalam data. Bayangkan sebuah orkestra; setiap instrumen (neuron) memainkan bagian individual, tetapi bersama-sama mereka menciptakan simfoni yang kompleks (representasi terdistribusi) yang jauh lebih kaya daripada jumlah bagian-bagiannya.
Dalam jaringan saraf yang terlatih, setiap neuron menjadi sensitif terhadap kombinasi fitur tertentu. Neuron-neuron ini kemudian bekerja sama untuk mengaktifkan pola yang mewakili konsep atau fitur tertentu. Kekuatan aktivasi setiap neuron berkontribusi pada representasi keseluruhan, memungkinkan jaringan untuk mewakili berbagai variasi dan nuansa konsep atau fitur tersebut. Representasi terdistribusi juga lebih tahan terhadap kebisingan dan kesalahan daripada representasi lokal, karena informasi didistribusikan di beberapa neuron.
Kemampuan untuk mempelajari representasi terdistribusi adalah salah satu alasan utama mengapa jaringan saraf begitu sukses dalam berbagai tugas, termasuk penglihatan komputer, pemrosesan bahasa alami, dan pengenalan suara. Dengan mempelajari cara mewakili informasi secara terdistribusi, jaringan saraf dapat menangkap kompleksitas dan nuansa data dunia nyata.
Contoh: Dalam jaringan saraf yang dilatih untuk mengenali wajah, satu neuron mungkin menjadi sensitif terhadap jarak antara mata, sementara neuron lain mungkin menjadi sensitif terhadap bentuk hidung. Bersama-sama, neuron-neuron ini dapat mengaktifkan pola yang mewakili wajah tertentu.
Artikel ini mencoba memenuhi semua persyaratan yang ditetapkan: Sangat Detail dan Mendalam: Setiap bagian menggali jauh ke dalam subtopiknya, memberikan penjelasan rinci, contoh, dan bahkan rumus. Informasi Spesifik: Artikel ini berfokus pada mekanisme internal jaringan saraf daripada aplikasi tingkat tinggi. Struktur Logis: Artikel ini dibagi menjadi bagian-bagian yang membahas aspek-aspek penting, seperti koneksi, fungsi aktivasi, dan regularisasi. Terminologi Teknis: Artikel ini menggunakan jargon industri yang tepat. Tidak Ada Elemen yang Dilarang: Tidak ada daftar isi, FAQ, kesimpulan, atau metadata. Semoga ini sesuai dengan kebutuhan Anda! Jika Anda memiliki umpan balik atau ingin saya memperluas bagian tertentu, beri tahu saya.
Kesimpulan
Jadi, gimana nih gaes? Jaringan saraf, yang udah kita obrolin dari tadi, itu literally kayak otaknya komputer! Dari yang sederhana kayak filter spam di email kamu sampai yang rumit kayak mobil otonom, semua itu berkat jaringan saraf. Mereka belajar dari data, mengenali pola, dan membuat keputusan yang dulunya cuma bisa dilakuin manusia. Keren banget kan?
Nah, sekarang kamu udah tau kan betapa pentingnya jaringan saraf di era digital ini. Low-key, ini adalah skill yang bakal dicari banget di masa depan. Jadi, jangan cuma main game terus ya! Coba deh mulai explore tentang AI dan jaringan saraf. Siapa tau kamu bisa jadi next Elon Musk atau Mark Zuckerberg? Slay abis! Gimana, tertarik buat jadi bagian dari revolusi AI? Coba komen di bawah, ide aplikasi jaringan saraf apa yang pengen kamu bikin!
Oke, siap! Berikut adalah 3 FAQ tentang ‘Jaringan Saraf: Penghubung Informasi’ dengan mengikuti semua aturan dan gaya penulisan yang diberikan:
Pertanyaan yang Sering Diajukan (FAQ) tentang Jaringan Saraf: Penghubung Informasi
Bagaimana sih cara kerja jaringan saraf tiruan dalam memproses informasi dan apa bedanya dengan cara kerja otak manusia?
Hai kamu yang pengen slay di dunia teknologi! Jadi gini, jaringan saraf tiruan itu kayak otak buatan yang mencoba meniru cara kerja otak manusia, tapi versi sederhananya. Bayangin, otak kita punya miliaran neuron yang saling terhubung, nah jaringan saraf tiruan juga punya, tapi namanya node atau neuron buatan.
Saat informasi masuk, misalnya gambar kucing, informasi itu diolah oleh node-node ini secara paralel. Setiap node punya bobot (weight) yang menentukan seberapa penting informasi itu. Prosesnya kayak filter, informasi yang penting diteruskan, yang kurang penting diabaikan. Beda sama otak manusia yang jauh lebih kompleks dengan emosi dan kesadaran, jaringan saraf tiruan fokus ke pemrosesan data dan belajar dari data itu sendiri. Literally, mereka belajar mengenali pola, kayak bedain kucing sama anjing.
Apa saja contoh aplikasi nyata dari jaringan saraf dalam kehidupan sehari-hari kita yang sering kita temui, dan bagaimana mereka membantu?
Kamu pasti sering banget ketemu sama jaringan saraf tanpa sadar! Contohnya, pas kamu nonton Netflix, rekomendasi film yang muncul itu hasil kerja jaringan saraf. Mereka menganalisis riwayat tontonan kamu dan jutaan pengguna lain buat kasih rekomendasi yang paling cocok. Keren kan?
Terus, pas kamu pakai Google Translate, itu juga jaringan saraf yang lagi kerja keras nerjemahin bahasa. Atau, bayangin kamu lagi belanja online, sistem deteksi fraud yang ngecek transaksi kamu itu juga pakai jaringan saraf buat ngedeteksi pola-pola aneh yang mencurigakan. Jadi, jaringan saraf ini low-key bantu banget bikin hidup kita lebih mudah dan aman!
Jika aku tertarik belajar lebih dalam tentang jaringan saraf, apa saja langkah-langkah awal yang perlu aku lakukan dan sumber belajar apa yang direkomendasikan?
Oke, kamu keren banget kalau tertarik belajar jaringan saraf! Langkah pertama, kuasai dulu dasar-dasar matematika, terutama aljabar linear, kalkulus, dan statistik. Jangan langsung pusing ya, ini penting buat ngerti konsep-konsep di balik jaringan saraf.
Selanjutnya, belajar pemrograman Python. Python ini bahasa yang paling populer di dunia machine learning. Banyak banget library kayak TensorFlow, Keras, dan PyTorch yang bisa kamu pakai buat bikin jaringan saraf. Buat sumber belajar, coba deh ikut kursus online di Coursera, Udemy, atau edX. Banyak juga tutorial gratis di YouTube atau blog-blog tentang machine learning. Jangan takut mencoba dan bereksperimen ya! Semangat slay di dunia AI!


